How I tried to invent a new query language feature and failed (because the old one worked fine)
A slightly unusual story of a fail I am not too angry with.
It was a part of the effort to create some sort of query language for fetching data from Wikipedia. I’ve been on and off the idea for half a year but recently decided to give it a more systematic resource. To make myself stay on track, I decided to describe my path as I go.
This article is written for my Substack, you can subscribe to it by email now!
By that time, the base was essentially in place. I wanted Wikipedia pages to be queriable in CSS-selector-alike language, incorporate content semantic-level selectors into it (sections, sentences, etc.), and, most crucially, select the most common and useful types of data in one expression.
As I started with that describe-as-I-go approach, it gave insights to straighten up a few loose parts of the language that were hard to explain. It also gave the possibility to estimate the effort necessary to take to describe internally complex structures with easy-to-remember and straightforward expressions.
After that last chapter (some three weeks ago, sorry, life catches us sometimes!), I proudly announced that the next plan is
[to] extend dictionary of supported selectors/concepts for some time: we need at the very least infoboxes and hatnotes; most probably, some of the other formalized elements, like navboxes.
And that’s where the things went weird.
The problem
So, what are those “infoboxes” and why are they so important?
It is a term to designate the most seemingly formal part of the Wikipedia article:
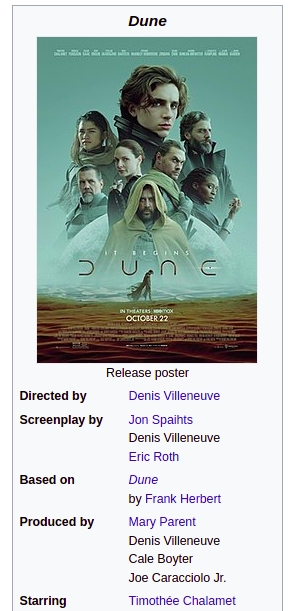
That’s the part of Wikipedia that creates a temptation to parse—and that’s how I was hooked up too, many years ago. Wikipedia infoboxes were my very first guess when I imagined that API like World.country("Ukraine").attr("area") should be available in open programming languages, using open data sources.
That’s why my very first project on the topic—Wikipedia parser for Ruby, still alive and quite powerful—was called Infoboxer. Its scope quickly grew wider than this part of the page, but the name stuck.
And so, I was returning to where it all started: looking into Wikipedia infoboxes parsing for WikipediaQL query language and trying to design parsing primitives for it—in a slow realtime, while writing this article.
When I started to write, the working title was Fantastic Wikipedia Infoboxes and How To Parse Them. Not the freshest approach, but it seemed to fit.
By the end of the article/new version development, I expected to have some new neat infobox selector (or maybe a few related ones). The details of how exactly it would be used to describe data were still unclear, but that’s what the “write about it, then implement” approach is for!
The implementation effort
So, I just opened some page and absentmindedly started to try to extract data from it with the tools I already had—expecting it to not work (or be extremely clumsy), so I’ll know where to look for missing parts.
To my slight awe, it was actually OK.
$ wikipedia_ql -p "Dune (2021 film)" \
'table.infobox >> table-data >> td >>
{ @row as "title"; text as "value" }'
Output (Note: I am humanizing YAML output a bit for the article, the real output is more regular yet takes more lines. YAML is the default output format because its structure is very human-readable; --output-format json is also supported.):
...
- "title": Directed by
"value": Denis Villeneuve
- "title": Screenplay by
"value": >
Jon Spaihts
Denis Villeneuve
Eric Roth
- "title": Based on
"value": >
Dune
by Frank Herbert
...
It is somewhat wordy (the wordiness is acceptable for occasionally-read language, I assume), but otherwise quite to the point. Looking at it as just a usual table and using already designed tools, one doesn’t need anything infobox-specific to fetch data.
I went to several more pages. The same extraction statement worked perfectly fine, both for turning the entire infobox into structured data and for extracting some particular value by field name:
$ wikipedia_ql -p "Dune (2021 film)" \
'table.infobox >> table-data >> { td[row="Budget"]; td[row="Box office"] }'
Output:
- $165 million
- $368.1 million
Finally, I met the infobox that doesn’t correspond to the model at all, still being structured: at the page dedicated to World War II, this structure can be seen:
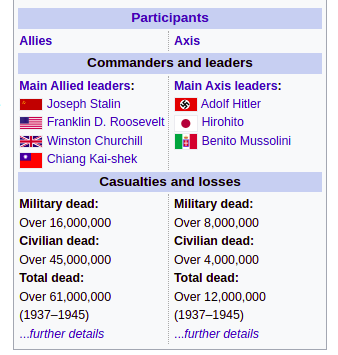
It is still obviously regular but doesn’t match the expectation of having a field name and a field value in each row.
But after some consideration, I remembered I had another trick up my sleeve: the table parsing heuristic I planned but not yet implemented on the previous approach to tables. What if table “normalization” would automatically turn mid-table full-row th into a row-level th for all subsequent rows? In other words, table-data pseudo-selector was adjusted to perceive the table above as this:
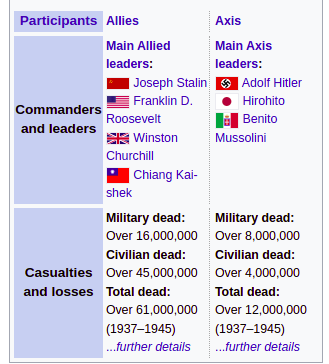
And that was all we needed to fetch some data from the table:
$ wikipedia_ql -p "World War II" \
'table.infobox >> table-data >> td[row^="Casualties"]'
Output:
- >
Military dead:
Over 16,000,000
[...skip...]
- >
Military dead:
Over 8,000,000
[...skip...]
Interestingly enough, both services providing structured data from Wikipedia—Wikidata and DBPedia—seem to fail to fully formalize data from this part of the page (Wikidata, DBPedia). This probably implies we are onto something here!
With that, and going through many more pages, it seemed… Good enough? I even spent several hours creating the showcase page—mainly to document the approach, but also to persuade my baffled self that it really works this way.
Some quirks do show themselves there, but most of the time, it is easy to handle in the data post-processing stage.
But wait, where is my cool infobox primitive to design?!
The fail?
As stated in the first paragraph, I am not angry at a failure to design a new primitive, but I still feel uneasy about it. My old Wikipedia parsing project had “infobox” in the project’s name—and the second one even wouldn’t have it is a named construct?!
But it also shifted my perspective significantly.
The “revelation” that led to WikipediaQL’s birth was the sudden understanding that Wikipedia’s HTML is much more regular and predictable than its source markup that I spent a good chunk of my 30th parsing. The “infoboxes fail,” from a certain point of view, is just logical.

There are many discrepancies between the HTML DOM model and the perceived data model of the Wikipedia page. Those discrepancies make straightforward web-scraping too tedious, asking for a specialized tool. I initially assumed that following the Wikipedia-specific structuring is the best way to handle these discrepancies.
I thought that defining first-class scraping primitives for infobox, navboxes, hatnote is the only way forward.
But it seems that the useful approach is more subtle. As accidental usefulness of table-data shows, we probably can stay in the “almost generic DOM” domain, enhancing it with some good heuristics matching the usual structure of MediaWiki content.
This will lead to a much smaller and more conventional “dictionary,”—which is also easier to master for library users. All in all, we shouldn’t forget that the terms for page elements like “infobox” are a domain language of Wikipedia maintainers, not of its readers.
I still consider some possibilities when looking at infoboxes (I spent too many years with them to let them go easily!). One of the possibilities is to introduce shortcuts/aliases in WikipediaQL: instead of writing table.infobox >> table-data >> td[row="Born"], one might want to do something like infobox-field[name="Born"].
In any case, it is something to think about down the road: a well-chosen base is more important to me now than rapidly growing the language to handle any demo-friendly case with just one word.
What’s next
I am not sure! Designing the thing that has so many cool potential purposes makes one greedy to invent all the features in the world. Programmers gonna program, you know.
The initial assumption behind the WikipediaQL is that the most non-trivial and useful part of it needs to be Wikipedia-specific, talking in the parlance of infoboxes, navboxes, hatnotes, and such. But the encounter with the “no need for infoboxes” revelation led me to rethink my course for now.
(Frankly, the development course is also affected by the fact that I am still not sure the project will find its users. It is fun to develop, though!)
I’ll try to look the new direction opened: maybe the generic-from-the-beginning is actually better? There are several equally useful albeit less known wikis. My favorite is Wikivoyage, which grew into a go-to resource for initial acquaintance with a new place when traveling. Wiktionary is quite cool too!
Also, I always liked the Fandom (nee Wikia) rich set of wikis dedicated to specific books, movies, and other topics; but unsure whether I want to get involved with them for experiments and demos. For one, the site is so ad-ridden now my Chrome is almost dying, even with AdBlock. Another thing to consider is that they seem not to advertise the MediaWiki API, and the REST part is not implemented/disabled there. WikipediaQL uses this API for page source fetching, though alternative approaches exist.
So, next time I might look into what it takes to apply WikipediaQL to other MediaWiki installations, starting from Wikipedias in languages other than English and going sideways from there. We’ll see!
I am eager for feedback; please don’t hesitate to drop me a line on anything related to the library or my writing!