Wikipedia as the data source: taming the irregular, pt.1
On challenges of designing the “query language” for a human-readable encyclopedia.
Some time ago, I posted a write-up on Wikipedia’s abundance of knowledge and approaches to extracting it programmatically. It was designated to be a gentle introduction to my new and still rough project, so here is a long-overdue continuation. Or the first part of it.
To reiterate on the where we are standing:
- …one should be able to write (in Python, Ruby, Haskell, whatever) something to the meaning of
World.country("Ukraine").attr("area")and receive a meaningful answer. For any/most of the “commonly known” facts. - Looking for a source for this data, one will quickly arrive at Wikipedia: it is crucial open storage of the human knowledge—or, at least, a table of contents for it.
- For programmable access, Wikipedia just falls short of the reach: it looks almost regular in many parts, but just irregular enough so that every attempt to fetch some data gets stuck in a tar-pit of tedious parsing and normalizing.
Starting from this point, that’s what I tinker with: would it be possible to design some approach, or API, or engine such that expressing “what I need from that Wikipedia page” just felt natural, and at the same time, performable by the computer?
Meet WikipediaQL
And that’s how WikipediaQL was born. It is still in its infancy but seems quite promising (at least for a proud new father):
pip install wikipedia_ql
from wikipedia_ql import media_wiki
wikipedia = media_wiki.Wikipedia()
print(wikipedia.query(r'''
from "Dune (2021 film)" {
section[heading="Cast"] >> li >> text["^(.+?) as (.+?),"] {
text-group[1] as "actor";
text-group[2] as "character";
}
}
''')
# [{'actor': 'Timothée Chalamet', 'character': 'Paul Atreides'},
# {'actor': 'Rebecca Ferguson', 'character': 'Lady Jessica'},
# {'actor': 'Oscar Isaac', 'character': 'Duke Leto Atreides'},
# {'actor': 'Josh Brolin', 'character': 'Gurney Halleck'},
# {'actor': 'Stellan Skarsgård', 'character': 'Baron Vladimir Harkonnen'},
# {'actor': 'Dave Bautista', 'character': 'Glossu Rabban'},
# ....
WikipediaQL-the query language uses a mix of CSS and CSS-alike attributes, allowing to operate on a level of HTML tags markup, as well as a level of the text structure (sections, sentences, text chunks), as well as Wikipedia-specific structures (infoboxes, navboxes, and data tables).
WikipediaQL-the engine uses MediaWiki API to fetch pages’ metadata and then pages’ HTML to pass through the query.

…I basically do, yes. Yet, I still believe some synergy might come from this project.
What I like most about it is how easy it is to achieve something useful with a very moderate amount of code. The first demo took some 400 lines of code and a couple of weeks to develop (a huge relief after several years and many thousands of LoC of my previous attempt). And yet, it was already powerful enough to solve my favorite “Rotten Tomatoes rating” problem (in WikipediaQL, it is done in the very first example in the README).
The most challenging (and still posing quite a few problems) is a need to make query language resilient enough to many small irregularities of the data. It can not be an afterthought or swept under the rug: after many (MANY) attempts, I believe it is the only way forward. We can not pretend the data is simple but should find primitives and combinators to express what it really is.
I plan to dedicate the next part (or several) to addressing some of the approaches to this problem of querying “natural for human” Wikipedia pages designs. Still, before that, some important question needs to be addressed.
Why bother?
Or, Isn’t there a formalized version of Wikipedia data already?
The answer is complicated! But yes, there are structured knowledge sources out there.
The semi-forgotten (by most of the general public) concepts of Semantic Web: RDF statements (subject-predicate-object triples) and SPARQL query language on them—are explicitly designed for describing open knowledge. So, there are several Wikipedia counterparts that use those technologies. The most notable is Wikidata, maintained by the same Wikimedia Foundation as Wikipedia itself.
It is tightly integrated with Wikipedia: every Wikipedia article nowadays has a link to Wikidata item in the sidebar; also, there is direct data transclusion from Wikidata here and there, like some page will contain in its source just `` call, which loads data into infobox from the corresponding Wikidata item.
As I stated in the previous article and elsewhere (for example, in this extensive Twitter thread), I do believe that Wikidata “is the most important project of the Wikimedia Foundation to the day. It is not yet to full possible capacity, but it is incredibly significant.”
And yet, for my next trick, I decided not to rely on it just yet (I will most probably expand my future attempts to it, too; my previous project did use both Wikipedia and Wikidata). The problem with Wikidata is that, as of now, most of the knowledge there is significant, but not yet interesting.
Two problems impend casual playing with Wikidata facts: discoverabilityand completeness.
NB: Here is a comprehensive article on data extraction from Wikidata on Towards Data Science, by Michael Li.
What I do instead
Speaking of discoverability: it is much harder to see what information is already there and how to go to it. Say, take Pink Floyd article in Wikipedia, and its counterpart in Wikidata. In Wikidata, you don’t see albums in that article; so, to uncover what info is available, you need to go to a particular album’s page, see what predicate is used to link it to the parent group. Only then can you start to build your query.
On the other hand, with Wikipedia, the info is already there; and with WikipediaQL you might say you have some odd variety of “WYSIWYG”: what you see is what you (can) get:
wikipedia.query(r'''
from "Pink Floyd" {
section[heading="Discography"] >> li {
a as "title";
text["\((.+?)\)"] >> text-group[1] as "date";
a@href as "link"
}
}
''')
# [{'date': '1967', 'title': 'The Piper at the Gates of Dawn', 'link': 'https://en.wikipedia.org/wiki/The_Piper_at_the_Gates_of_Dawn'},
# {'date': '1968', 'title': 'A Saucerful of Secrets', 'link': 'https://en.wikipedia.org/wiki/A_Saucerful_of_Secrets'},
# {'date': '1969', 'title': 'More', 'link': 'https://en.wikipedia.org/wiki/More_(soundtrack)'},
# ...
Depending on the angle of view, the discoverability may or may not be a problem for you, but the completeness problem is doubtless.
The thing is: as of now, you might reliably expect that for every Wikipedia article, there is a corresponding Wikidata item, and (less reliably, but still pretty safe bet) that the info in the page’s infobox would be in Wikidata, too. In a lot of cases, that would be it with Wikidata. But in Wikipedia, the things are just starting from there: all in all, the entire article is full of facts!
While a decent part of it is just a free-form text (and extracting facts from that would be lead to the wast hills of NLP, entity recognition, and such), there still is not a small amount of formal enough structure for algorithmic extraction. Even the textual part has small, regular structures like my favorite “just find a phrase about ‘Rotten Tomatoes’” example above. Besides that, there are lists, tables, galleries, sections… Most of it is not in Wikidata yet, but it can be fetched from Wikipedia already, just like that:
wikipedia.query(r'''
from "Kharkiv" {
section[heading="Climate"] >> table >> table-data >>
tr[title="Daily mean °C (°F)"] >> td {
@column as "month";
text as "value"
}
}
''')
# [{'month': 'Jan', 'value': '−4.5\n(23.9)'},
# {'month': 'Feb', 'value': '−3.8\n(25.2)'},
# {'month': 'Mar', 'value': '1.4\n(34.5)'},
# {'month': 'Apr', 'value': '9.7\n(49.5)'},
# {'month': 'May', 'value': '16.1\n(61.0)'},
# ...
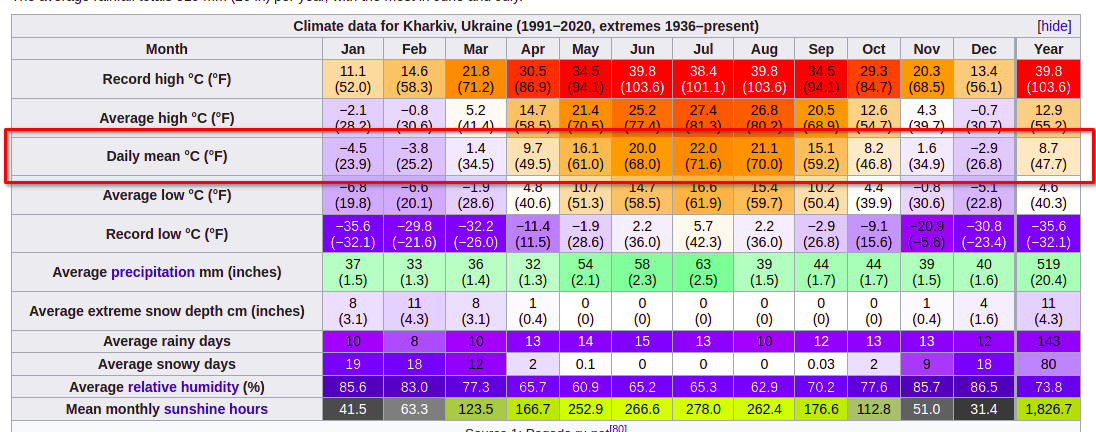
The climate data above is taken from this table on my city’s page. Almost every city article in Wikidata has one. Try yours!
Now what?
With that ground laid for developing WikipediaQL and explaining it on the road, in the future, we will look into how the balance between regular query language and irregular source structure can be kept. We’ll see what elements the query language might consist of and what lengths the implementation might need to go.
Follow me on Twitter or subscribe to my mailing list to see the road together.