ChatGPT have killed my passion project and I am fine
Part 1: Welcome to reality
…so, the story goes like this:
Just a few months after ChatGPT became an Internet darling, I suddenly understood that it (and LLMs in general) rendered my biggest personal project irrelevant.
One might ask: so what? In the ever-changing industry, nobody has a steady ground underneath their feet. A lot of software projects probably find themselves superseded or bypassed by a sudden new technology, and not only modest “personal” ones but somebody’s billion-dollar hopes!
I hear you. Yet, for me, the thing was pretty big. It wasn’t some weekend experiment but a large tree of projects and ideas I climbed for almost ten years. A project of passion that I almost expected to remain lifelong.
And yet, suddenly, it was all done and gone. What might one feel at that moment? What would they think?
Many different things! But first, what was the project?
The dream of reality
I’ve already told the story of my Big Project (while still attempting to do one more iteration of it), but to recap it briefly:
I was inspired by the Wolfram language’s idea of having “common sense” data about the world as a part of the language/library1. And I wanted to reproduce it in Ruby (in which I think) and, of course, using open technologies and open data.
A bit of “TMI”: I half-seriously believe that this project might’ve cured me of something akin to midlife crisis, at least a professional one.
I consider myself a writer, first and foremost—a writer who mostly writes in programming languages2. And while I can enjoy writing code for “regular” projects (small and medium-sized pragmatic product companies are my usual employers), at some point in life, at the beginning of my 30th3, I started to lose interest.
Writing, for me, is all about looking at things closely, having some insights about them, and sharing them with others: for them to have and share their own insights, and that’s how the entire human culture is built if you’ll excuse my pathos. For a passionate programmer of my type, just building useful products is never enough; trying to uncover something new and exciting to share with other programmers was what I missed.
So, the problem I dedicated myself to was the idea that all the common knowledge should be accessible programmatically through some universal API.
Naive as I was, I believed that I saw a clear (if a very long) path to the goal:
- start from Wikipedia (which is obviously a “table of contents” of human knowledge);
- develop a way to extract data from it;
- then, think of a nice Ruby API to represent all kinds of data generically (without, of course, introducing concrete classes like
Cat,City, orMolecule); - then, add other open data sources (OpenStreetMap, weather, currencies, animal species, …) and gradually add API for them.
Very sketchy, yes, but, on the other hand, there is no need for a more detailed plan for a solo developer looking for a passion project: you see your first step and possible future, so—
The first step—digging into Wikipedia—took a lot of work. But on the bright side, I believed that by-products of moving towards my distant goal should be useful by themselves.
Sooner or later (much later than it was estimated… like, years later), I developed a stack of libraries that I was quite proud of:
- MediaWiktory: a low-level client for MediaWiki’s peculiar API, which allowed to use all of it in the exact terms it was meant to be used;
- Infoboxer: a semantic client for Wikipedia (and any similar MediaWiki), with a full-strength MediaWiki markup parser, a parse tree for any page’s content, and an XPath-like query language for this tree;
- a few “side-quests,” not directly related to the main direction, but ones that I wanted to have at some point: TZOffset and Geo::Coord data types and tlaw (aka “The Last API Wrapper,” a declarative HTTP API client description framework);
- and a “crown jewel” of the effort, the project/library named Reality — a (forever) early draft of what I really wanted to achieve.
I went through several iterations, moving from “cool on demo, breaks on any non-trivial case”:
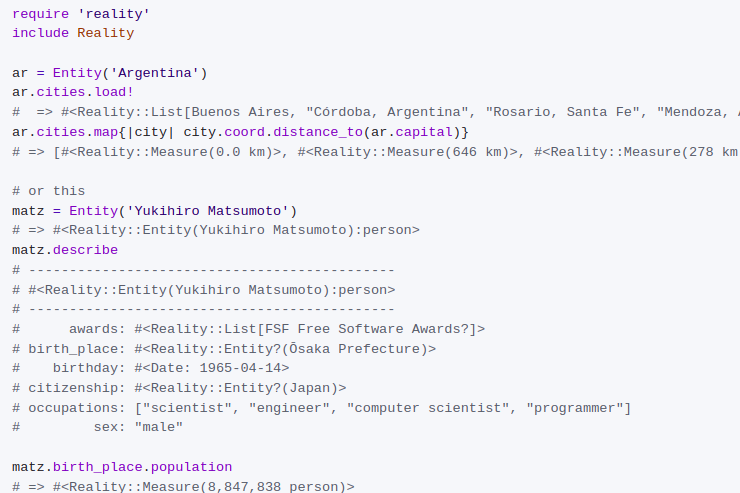
…and towards more formal (and less demo-friendly until you are fully sold on the entire “describe the world” project):
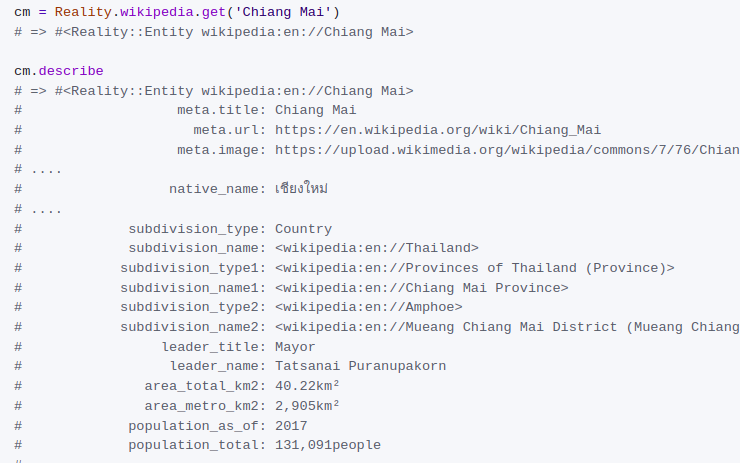
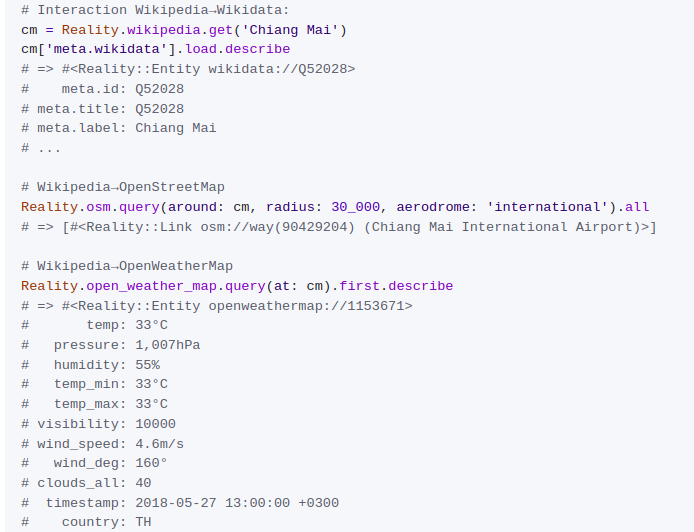
As you might distinguish from screenshots, those last demos already demonstrated the ideas of interaction with many open data sources in what felt like a clear and extendable way. I hoped to cover more with each next iteration.
The project brought me several hundreds of GitHub stars, a lot of experience, several moderately successful conference talks— And not much more.
For “some reason” (hehe), nobody in the community seemed to care about using my precious libraries—neither more pragmatic Wikipedia clients (though I sought to put nice and practical examples in README and various documentation) nor the Reality™ itself.
Given that it was an early prototype—and still, I had some hopes (or, rather, dreams) of a vibrant community emerging around the idea. Maybe even attracting people from other languages to look at Ruby (which gave me the ability to build a nice API and do it efficiently!) in the new light.
There was some initial spark of enthusiasm and several people trying to contribute—but not for long. One of the reasons was the inherent complexity of the task at hand. The API was looking nice and easy (and that was attractive, at least to some), and it solved a task that is easy for a human, so the contributors came in the hope that adjusting or adding something would be as simple as it intuitively should— and were met with a need to understand many domains, APIs, and concepts that powered it all.
That’s one of the constant and important pitfalls I have with my passion projects. It is frequently said that the most popular projects are those that make easy the thing that felt complicated. My projects tend to make simple what “intuitively” looks simple, but is complicated inside.
So a lot of those who look at those projects are disinterested because they don’t believe there was a significant problem to solve (after several months of work on Infoboxer, one of the first comments after it publishing was along the lines “it is just a glorified HTTP client, nothing one can’t do in a few hours”). Others know that the problem is complicated and work on its part for years— And they aren’t interested in solutions that designed to be appealing for the common public.
But that was not the only reason for the project staying in a forever “curious demo” stage.
The reality check
After a few-years-long marathon (the first commits of the Infoboxer were in May 2015, and the last attempt to revive Reality was a release and talk prepared for RubyConf India’18), I was somewhat out of steam and wanted to reevaluate my options and the way to move forward.
I was still fond of the general idea, yet I am not of the kind who would polish their magnum opus in the ivory tower for decades. Like a normal writer, I want to get published—not for fame or money, but because ideas and texts are worth crap unless they are circulated, perceived by others, and produce other ideas. In the area of open source, this means not only putting a thing on GitHub but also seeing people using this thing and trying to adjust it to their own needs.
So, I identified some problems that, in my opinion, led to the fact that my “cool” projects haven’t received as much attention as they “deserved.”
The first problem was societal: at that point in time, it was obvious that the Ruby community was mostly entrenched in the “web development” domain, where access to rich open data was not that important. Especially the kind of access that is not super-robust or performant: theoretically, one can use Reality/Infoboxer to, say, populate a database of TV show episodes (while developing a new show-tracking service), yet various irregularities in data and formatting would urge one to look for a specialized data source.
The “you can fetch a lot of various data kinds, yet not always robustly” seems more appealing for an environment with a lot of experimentation, data-driven research, one-off demos of interesting visualizations, and such. The obvious choice was to court the Python/data science community.
The second problem (which I wasn’t sure even switching the language/community would solve) was that I did not have many pragmatic examples in mind to quickly demonstrate how having access to “all common sense data” in a homogeneous API would be useful. My various go-to demos (like “distances between cities” or “discographies of artists”), arguably, are better solved with specialized APIs/datasets. I still believed that “it should be done,” yet struggled to explain why. Which always felt weird!
(There was also a third problem, purely technical: however fond I was of my powerful markup parser, it turned out to be a dead-end. But I already discussed that in the article which was a start of the project that hoped to solve it.)
So, once on vacation at sea with my family, I had an idea that, at the moment, looked like moving forward in the chosen direction AND being more pragmatic.
A postcard from Ukraine
Please stop here for a moment. This is your regular mid-text reminder that I am a living person from Ukraine, and a bit of useful related information.
One plea. If you are in the US, please call your representative! The bill to provide help to Ukraine will be discussed in the Senate soon.
One fundraiser. Ambulances for UA: “Fundraiser for the 6th vehicle has begun: the target is 15000€ and we already have 590€ in the bank!”
Scaling to the human size
So, once on vacation at the sea with my family, I had an idea.
That day, I looked at the weather forecast, saw a notification about a “4-ball storm,” and understood that I didn’t have a clue about whether it was big or small and what I could compare it to.
And so the idea was born.
I called it “humanescale.” The gist was just a library/code/tool that would be able to interpret numbers—any numbers—in a context that made them clearer for humans.
Like, you tell it “4-ball storm,” and it provides you with an explanation. You tell it “6 feet,” and it tells you (a European not fluent in Imperial measures) how much it is in centimeters, but also that it is the height of a reasonably tall male and between two and three adult steps. You tell it “3 km,” and it explains that it is half an hour walk, and even tells (having enough information) “that’s approximately from your city’s center to that park.” You tell it, “no, 3 km height,” and it helps to imagine that.
And so on, not limited to distances (they were just for starters): it should’ve allowed you to imagine whether “5 tons of grain” would take a lot of space, or how long you could travel in a car having 100 liters of petrol, or even complex things like “was 100 yen in 1980’s Japan a lot of money or not” or “is 29 Celsius in March hot in Barcelona.”
That was again about the “common sense knowledge” and “understanding the world.” I believed that having such a tool/API would be helpful in many situations, from reading books to understanding news, from planning travels to learning various professions.
And, of course, I believed that I knew how to do it! (Well, again, “first steps and then vague direction,” but still.) Wikipedia, while properly crawled, would’ve been a perfect source of numbers from various domains; then, again, more specialized services could’ve been added (like OpenStreetMap to provide distance and area comparisons, WorldBank API to answer economic questions etc., etc.). Then, parsing a text of simple queries to understand which domain it belongs to seemed a relatively simple (and curious) task; and then, choosing good answers for the domain could be found— well, “somehow, we’ll see when we have more data.”
For that “data” step, the former “reality” (in its new, smaller, and Python-based incarnation) would’ve been an underlying mechanism, but the “showcase” would be pragmatic. In my usual delusion of grandeur, I could’ve imagined it as a popular library, paid API service (“I smell startup!”—because everybody should have one), a mobile app, maybe an embedded service for prominent media—
So, I, again, started with a parser for Wikipedia (because, of course, no Python parser was good enough for my goals!). This time, I used an HTML representation of wikipages with a quick hack I named WikipediaQL.
The initial release (of a draft hacked in 2 or 3 days!) suddenly drew substantial attention on GitHub and HackerNews. It kinda derailed the whole quest: I dived into developing that query language/library and writing about it. That year, I decided to write more in a blog, and “writing while building something” is a known strategy to entertain readers, and WikipediaQL provided a lot of immediate challenges, both head-scratching and solvable.
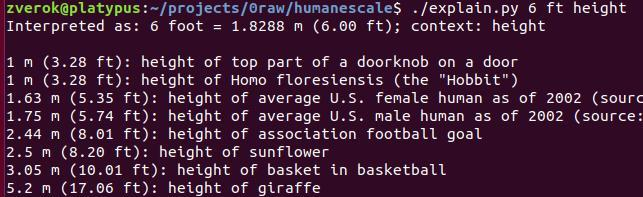
At the same time, my meek attempts to use WikipediaQL for prototyping humanescale produced quite underwhelming results:
That (unpublished) prototype used the data effortlesly extracted from the “Orders of magnitude (length)” page to “explain” some lengths in human terms. Wikipedia has a whole lot of such pages for different measures, so I had high initial hopes to solve a big part of the task in a uniform way!
I mean, it kind of “worked”, but the result were neither interesting nor helpful.
So, putting humanescale aside “for now,” I proceeded with WikipediaQL for a few months (on and off) with a few releases and a few blog posts (1, 2, 3, 4). Truth be told, while I saw a positive effect of the “develop in public” approach on my thinking and design decisions (some things become apparent when you are trying to explain them and put in a clear narrative!), I never enjoyed much attention to the library or the posts after that initial outburst of stars and likes.
It seemed—again—that I found the idea that was entertaining on the first demo, and then— nobody knew where to use it or even cared to consider. Even following somebody else’s journey (which I honestly tried to make entertaining) of solving some real-world problems (which I honestly believed were interesting) didn’t draw much of an audience.
Anyway, I never learned whether following this path long enough (at least to robust version 1.0) would bring me to an interesting place in terms of the product or collaboration because, you know—
Between my last published WikipediaQL article and the next time I was able to write into my blog, something have happened:
Many months later, when I started to have a bit of free time at night to pursue my pre-invasion interests (or, one might say: “a bit of time I needed to occupy with something other than doomscrolling”), I was involved back in Ruby development, but that’s not the reason why I never returned to WikipediaQL or humanescale.
The reason is that, of course, the whole approach was wrong.
So close, so far
In hindsight, I fell prey to the obvious fallacy: try to model an open domain with some classes and modules, hoping to “Pareto” my way into it.
Of course, in my fourth decade of life and second decade of professional software development, I was not naive enough to try an “OOP 101” approach of creating a class per real-world entity and an attribute per its characteristic. I still believe some generic entity-modeling ideas from the latest versions of Reality to be worthwhile.
On the other hand, I was naive enough to believe that at least some approaches to generic real-world data could be formalized. To that data, which broke every eleventh example after ten of them worked perfectly. To that messy, live, diverse, inconsistent, excessive, ever-changing data that has its best description in various “Falsehoods programmers believe about” lists.
I understand that many readers might be confused about how the grown-up man and supposedly a professional programmer even started these megalomaniac projects in the way I describe it (and not the proper way, which we are getting to).
In my defense, I always focused rather on some pragmatic, or at least shareable steps and ideas that would lead me somewhere in the general direction of the goal.
I actually still think that both MediaWiktory-Infoboxer projects pair, and WikipediaQL had some interesting solutions and usages. I even used some later prototypes of Reality for some moderately realistic tasks, like cleaning up data for some poetry festival and consulting Wikipedia to place the poets on map (and developed a fun small tool tool on the way).
Even if neither of the projects is heavily used currently (and I seriously doubt it will change), it was years well spent. I developed an understanding of a lot of things about APIs, libraries, development practices— and the world I was trying to put into the API.
I also gathered some deeper (if still shallow) understanding on the scale and scope of the problem of the “common sense data,” gathering it and making conclusions amout it. After years of hacking into APIs and parsing, I had a very strong hunch that it should—and once would—be solved differently.
And, of course, it was.
Soon after everybody started talking about ChatGPT and other LLMs (and even before I had a chance to play with it myself—I wasn’t too eager, to be honest, yet I followed the theory and examples as a curious bystander), I had a consistent internal explanation of why this thingy was the right way to the goal that I looked for years (and all in the wrong direction).
I want to share some of my layperson understanding of the matter (and the optics that allowed me to make peace with the whole machine learning domain, which I was extremely skeptical about some decades ago).
As it happens to me all the freaking time, what was intended to be a moderately long blog post, once I start, turns into a series. So— Till the next part!
…Which would still not give the final “revelations” (or rather musings of a man behind his middle age and still in love with all things programming), but will get closer to it by describing another area of interest I pursued for several years.
In parallel with the “reality” mirage, I managed to lure myself into another “project of a lifetime” (yeah, there were two of them) related to natural language processing. And that, probably, was the big turning point for developing my current understanding of machine learning and its relationships with “classic” software development.
You can subscribe to my Substack to catch the next part or follow me on Twitter.
Thank you for reading. Please support Ukraine with your donations and lobbying for military and humanitarian help. Here, you’ll find a comprehensive information source and many links to state and private funds accepting donations.
If you don’t have time to process it all, donating to Come Back Alive foundation is always a good choice.
If you’ve found the post (or some of my previous work) useful, I have a Buy Me A Coffee account now. Till the end of the war, 100% of payments to it (if any) would be spent on my or my brothers’ necessary equipment or sent to one of the funds above.
-
As far as I can remember, this long article with many demonstrations of the idea was what struck me first. ↩
-
After some Reddit comments I understood that this phrase (which in its previous version also had an ironic “occasionally writes in programming languages”) is not clear enough, making an impression of a person who writes books and sometimes codes. I am a professional developer with a PhD in CS and 20+ years of the full-time software development experience, which mostly writes code, yet perceives coding as writing. (I do write fiction/poetry sometimes, but it is a side activity in which I am not that successful.) ↩
-
Maybe a bit early for a mid-life crisis by today’s standards, but I always was an early bloomer! ↩